MagiCompiler深度解析:从torch.compile局部优化到全局调度的技术跨越
三年前,我第一次用torch.compile编译大模型时,以为这就是终点。GraphBreak、显存溢出、算子碎片——这些问题让我意识到,局部编译的天花板远比我想象的低。
困局:速度与显存的二选一难题
大模型开发者都懂这个痛:要速度,显存爆炸;省显存,计算效率被同步和流水线气泡拖垮。原生torch.compile面对复杂跨层优化和FSDP显存管理时,始终力不从心。
这不是某个API的缺陷,而是局部编译范式的根本局限。
突破:MagiCompiler的全局调度架构
Sand.ai开源的MagiCompiler彻底改变了这个局面。它基于torch.compile深度优化,实现了推理期整图捕获与训练期FSDP-Aware整层编译。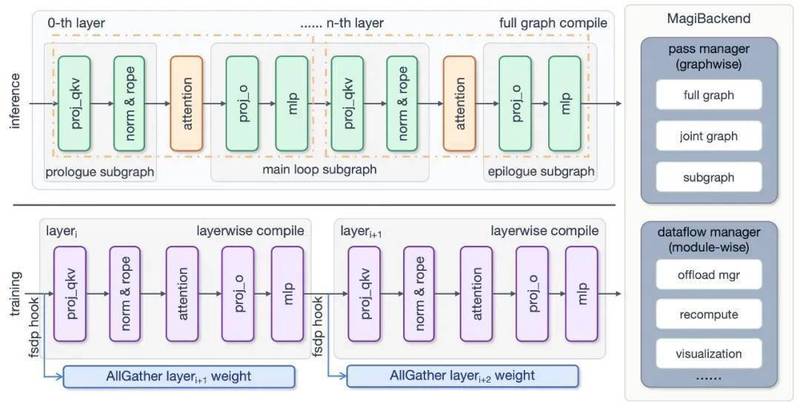
核心创新在于CompilerasManager理念:编译器从单纯的算子优化器进阶为全局管理器,全面接管计算调度与显存的生命周期。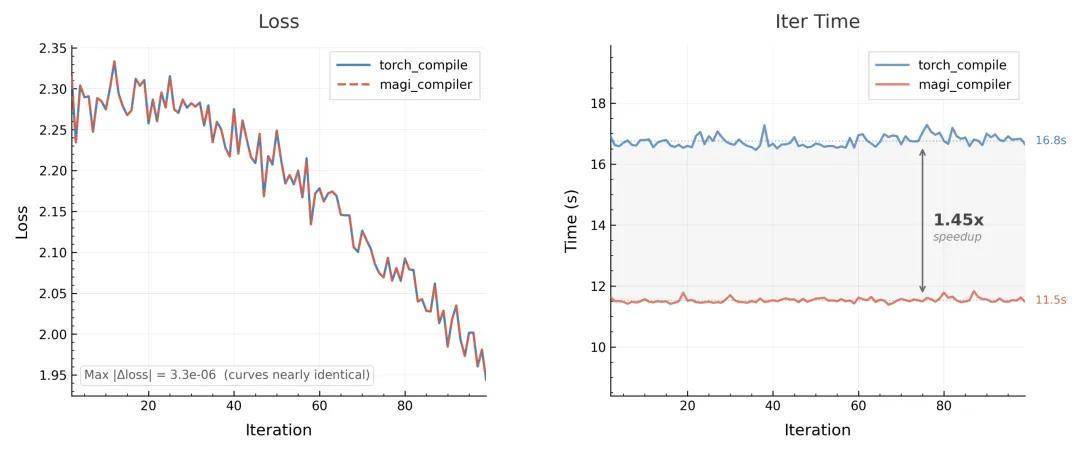
技术拆解:三大核心能力
第一,整图与整层编译。推理期捕获完整计算图,最大化TransformerBlock内算子融合空间。训练期利用FSDP特性,将TransformerLayer作为编译单元,执行激进跨算子融合。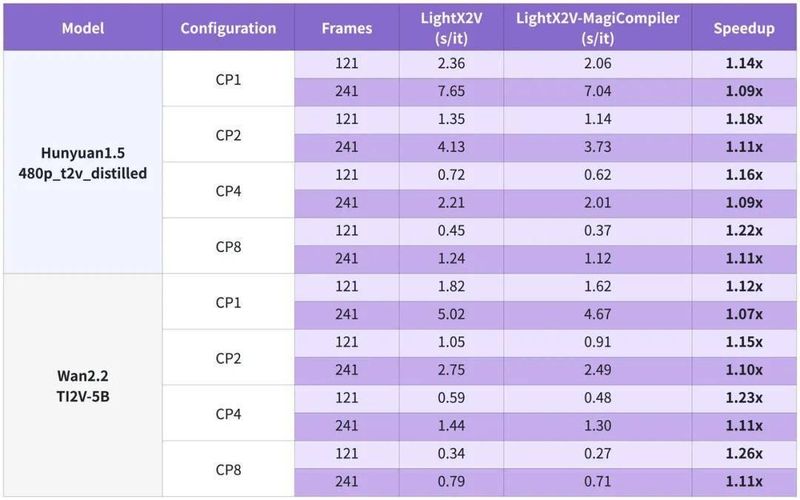
第二,启发式重计算。框架自动分析计算图,智能识别MatMul、Attention等计算密集型算子,优先保留输出。对显存密集型算子自动在反向传播时重计算,从根本上压缩显存峰值。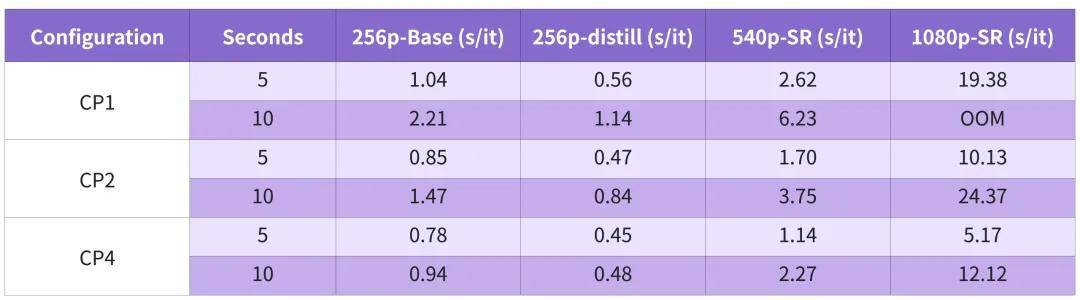
第三,JIT极致Offload调度。基于Profiling数据,将最划算的权重贪心地常驻GPU显存。调度器逆向推导精确预取时间表,卡在计算前最后一刻完成权重拉取,消除流水线气泡。
性能验证:实测数据说话
训练端:直接带来44.7%提速与6.2%显存下降,精度完全对齐。推理端H100上比LightX2V快9%~26%。RTX5090显存受限场景下,daVinci-MagiHuman超大模型跑出近乎实时速度。
接入体验:一行代码的工程哲学
强悍性能不代表复杂接入。仅需两个装饰器即可完成接入。magi_compile装饰TransformerBlock,无需修改模型源码。内置自省工具链,所有编译产物持久化为可读文件。
MagiCompiler正在证明:torch.compile迈向全局调度的巨大潜力已变为现实。这为大模型与多模态架构的规模化落地提供了坚实基础设施。
